Visual Studio and the BOM
- BOM causes problems in the middle of a document
- Method to check and convert the encoding
- BOM causes problems at the beginning of a document
New files created in Visual Studio (and Windows Notepad and many other Windows programs) are encoded in UTF-8-BOM, where the BOM is EF BB BF in hex, which is the encoding of the code point U+FEFF in UTF-8.
BOM causes problems in the middle of a document
In fact, this won't cause problems in most cases if you are writing .cs, .html, .js, .css and so on, since the compiler, the web can understand the BOM.
But if you are using Visual Studio to write html templates, which are compiled, rendered, and then inserted into web pages. This does start to cause problems. Or to be more generic, when a document with BOM is included in another document, that is BOM in the middle of a document, causes problems.
When there is no special logic regarding BOM or white spaces, each BOM effectively becomes a  (65279 is FEFF in hex) in HTML, and may introduce one extra text node depending on the surrounding html, which often breaks the designed UI.
Here are the screenshots of BOM shown in Dev Tools:
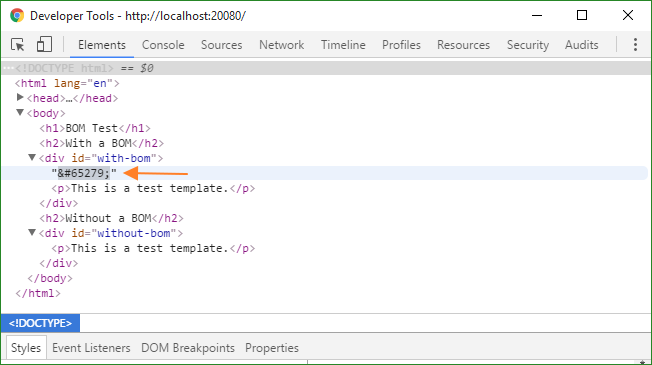
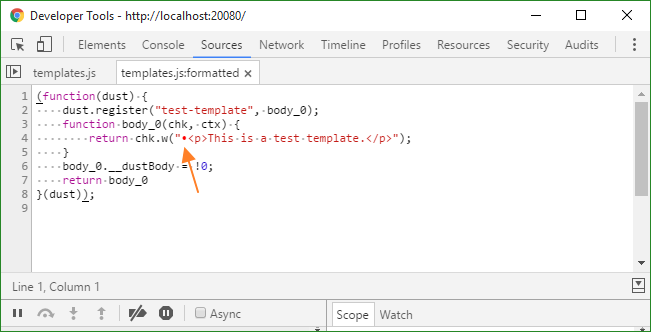
Note that BOM is an invisible character, or zero width no-break space. The red dot shown in Sources tab of Dev Tools is just a feature of Dev tools as an indicator of such unusual character.
And here is an example of the BOM breaking UI (note the extra blank line in the first box):
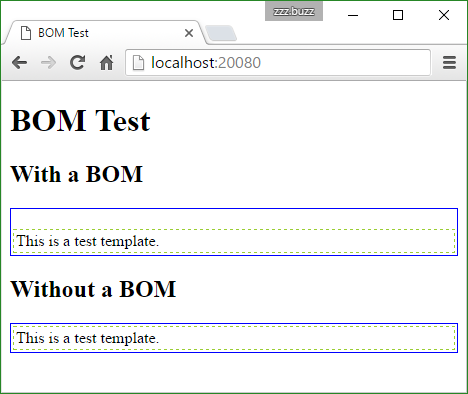
From the screenshot above, we may see that the BOM introduced an extra blank line into UI. As to the reason, it's caused by the BOM introducing an extra text node into DOM, and though BOM is also categorized as white spaces, a line box will be rendered for it alone, unlike spaces or tabs between DOM nodes, which won't be rendered into a line if appearing alone.
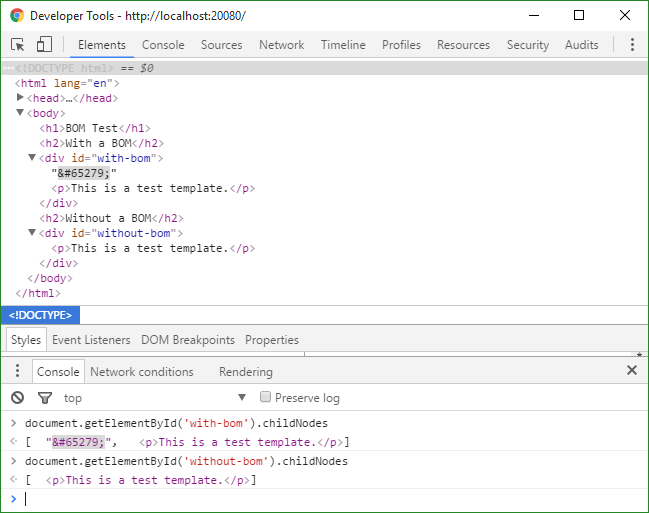
See this on JSFiddle.
Related questions
Here are some related questions about BOM on StackOverflow:
- How to avoid echoing character 65279 in php? (This question also relates to Javascript xmlhttp.responseText (ajax)) - Stack Overflow
- Why is appearing in my HTML? - Stack Overflow
Method to check and convert the encoding
To check and convert the encoding of a file, I'm using Notepad++. Encoding of current file is shown at the bottom-right, and encoding conversion is available in the Encoding menu.
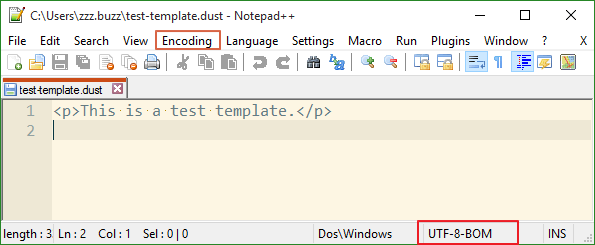
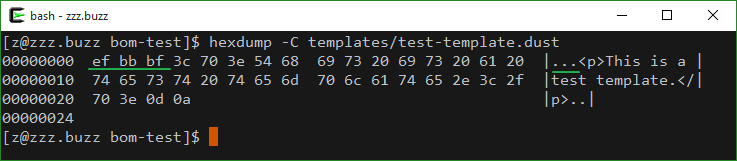
Besides, to check the encoding or existence of BOM, we may also choose to check the hexadecimal dump of the file with hexdump or tools alike.
Or use dedicated tools which determine file type like file command.

To convert text encoding using the command line, we may refer to iconv. But it's not really useful in this case as the existence of BOM cannot be specified using iconv even if it's BOM aware, see BOM in iconv for details.
iconv -f UTF-16 -t UTF-8 inputfile > outputfile
BOM causes problems at the beginning of a document
In fact, UTF-8 always has the same byte order, and a BOM makes no difference to the endianness. In addition, the use of a BOM will interfere with any protocol or file format that expects specific ASCII characters at the beginning, such as the use of #! at the beginning of Unix shell scripts.
So even at the beginning of a document, a BOM may cause problems. The best practise is to avoid it whenever possible. This is also recommended in the Unicode Standard:
Use of a BOM is neither required nor recommended for UTF-8.
See the following for details: